

Få adgang til AI Arena datasættene
Platformens spørgsmål og præferencer er tilgængelige på dansk, engelsk, fransk og forventes udvidet i fremtiden til blandt andet at inkludere svensk. Spørgsmålene afspejler organisk brug – ikke kunstige spørgsmål. Disse datasæt er offentligt tilgængelige på data.gouv.fr og Hugging Face.
Modeludgivere, forskere, virksomheder, nu er det jeres tur!
Vis os, hvordan du bruger datasættene
Alle spørgsmål og svar
Alle reaktioner på beskeder
Alle de udtrykte præferencer
Hvordan bruges disse data?
Eksempler på brug af AI-arena datasæt
Bunka.ai-teamet gennemførte en storstilet undersøgelse af bruger-AI-interaktioner på chatbot-området, hvor de kortlagde dominerende temaer, nøgleopgaver og balancen mellem automatisering og menneskelig forstærkning. Deres analyse, der er baseret på 25.000 reelle samtaler, giver en sjælden empirisk indsigt i, hvordan mennesker rent faktisk bruger AI.
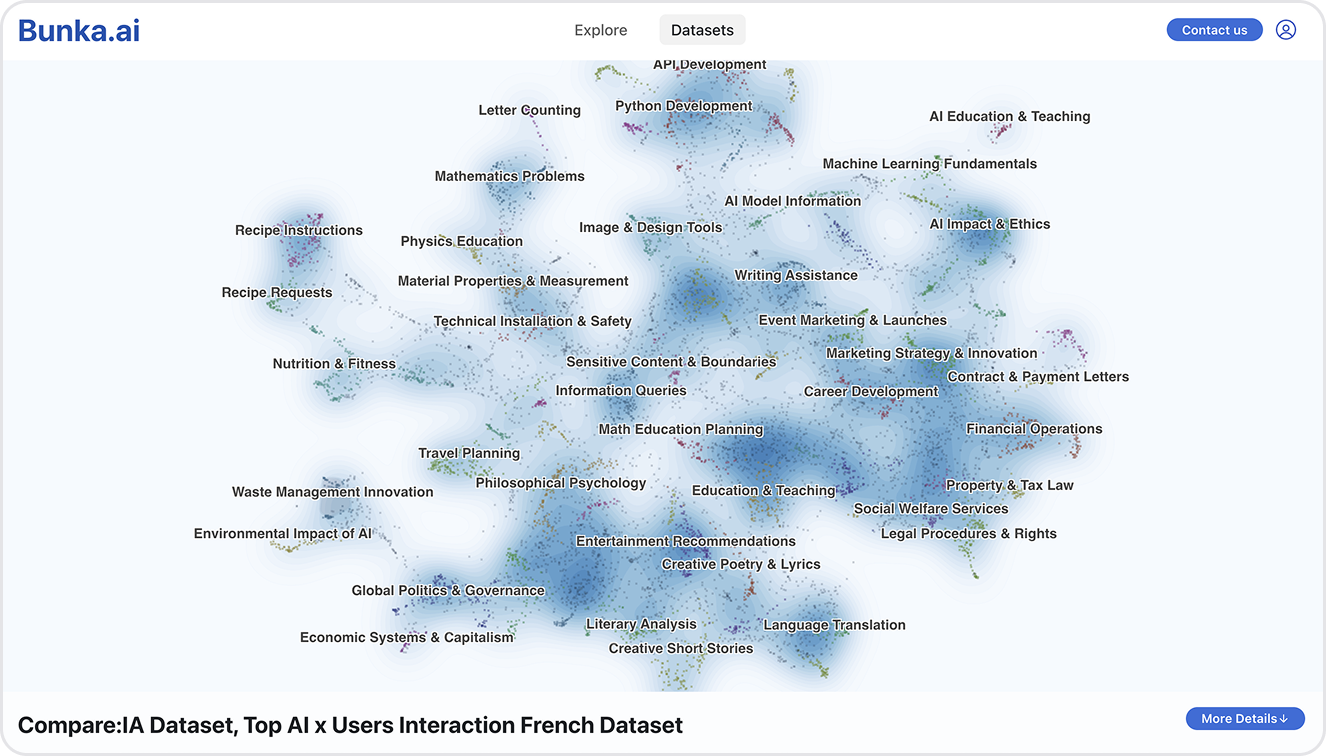
Interaktiv visualisering af samtaler, hvor hver klynge repræsenterer et tilbagevendende tema, som brugerne diskuterer (f.eks. uddannelse, sundhed, miljø eller endda filosofi).
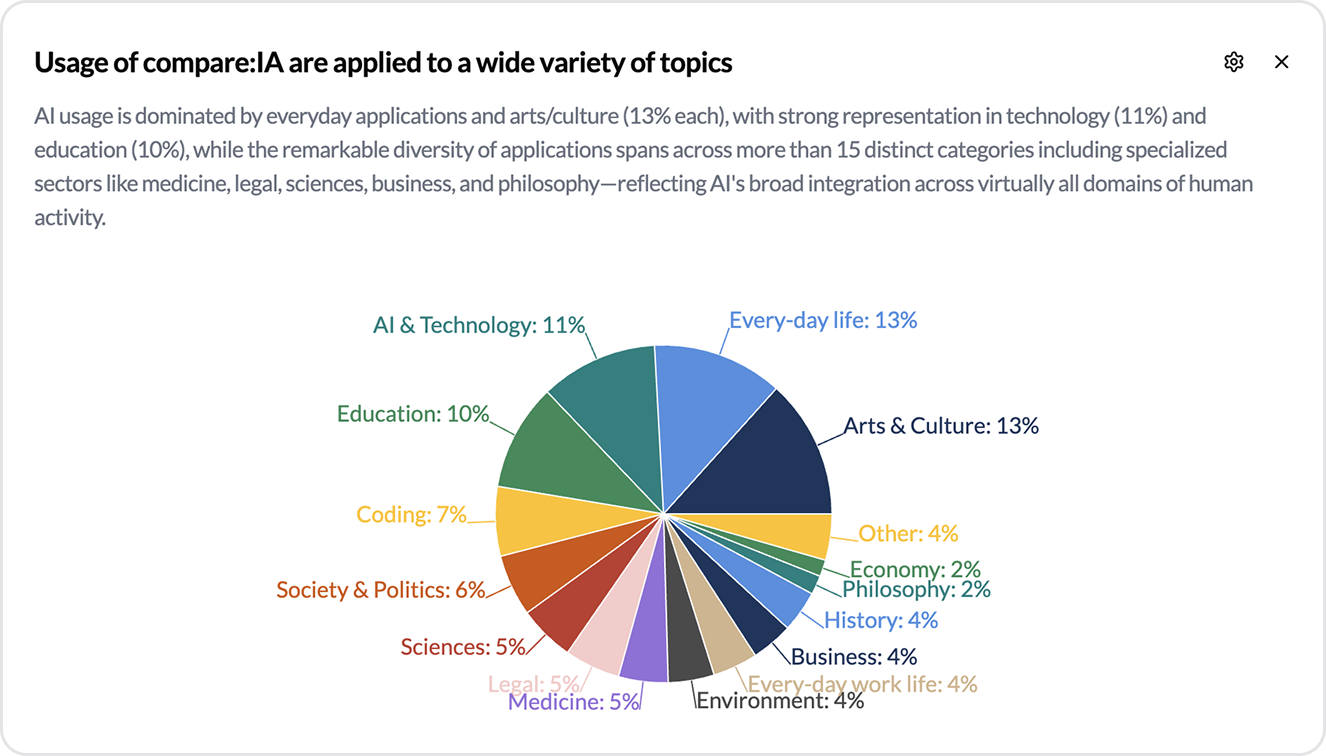
Analyse af brugeres samtaler med registrering af opgaver (oprettelse, informationssøgning osv.), emner (kunst og kultur, uddannelse osv.), komplekse følelser (nysgerrighed, entusiasme osv.), sproglig tone (formel, professionel osv.)